Bibliothèque de points de contrôle Snowpark¶
Snowpark Checkpoints est une bibliothèque de tests qui valide le code migré d”Apache PySpark vers Snowpark Python.
Conditions préalables¶
Pour utiliser Snowpark Checkpoints, il convient de configurer un environnement de développement Python. Les versions de Python prises en charge sont les suivantes :
3,9
3,10
3,11
Note
Python 3.9 dépend de la version 1.5.0 du client Snowpark. Python 3.10 dépend de la version 1.5.1 du client Snowpark. Python 3.11 dépend de la version 1.9.0 du client Snowpark.
Vous pouvez créer un environnement virtuel Python pour une version particulière de Python à l’aide d’outils tels que Anaconda, Miniconda, ou virtualenv.
Installation de Snowpark Checkpoints¶
Installez le paquet Snowpark Checkpoints dans un environnement virtuel Python en utilisant conda ou pip.
Utilisation de conda :
conda install snowpark-checkpoints
Utilisation de pip :
pip install snowpark-checkpoints
Si vous préférez, vous pouvez également installer les paquets individuellement :
snowpark-checkpoints-collectors - Utilisez ce paquet pour collecter des informations sur les DataFramesPySpark.
Utilisation de conda :
conda install snowpark-checkpoints-collectors
Utilisation de pip :
pip install snowpark-checkpoints-collectors
snowpark-checkpoints-hypothesis - Utilisez ce paquet pour créer des tests unitaires pour votre code Snowpark basé sur des données synthétiques générées automatiquement, suivant les schémas DataFrame collectés à partir du code PySpark original.
Utilisation de conda :
conda install snowpark-checkpoints-hypothesis
Utilisation de pip :
pip install snowpark-checkpoints-hypothesis
snowpark-checkpoints-validators - Utilisez ce paquet pour valider vos DataFrames convertis par rapport aux schémas collectés ou aux DataFrames Snowpark exportés générés par la fonctionnalité du collecteur.
Utilisation de conda :
conda install snowpark-checkpoints-validators
Utilisation de pip :
pip install snowpark-checkpoints-validators
snowpark-checkpoints-configuration - Utilisez ce paquet pour permettre à
snowpark-checkpoints-collectorsetsnowpark-checkpoints-validatorsde charger automatiquement la configuration des points de contrôle.Utilisation de conda :
conda install snowpark-checkpoints-configuration
Utilisation de pip :
pip install snowpark-checkpoints-configuration
Utilisation du cadre¶
Collecte d’informations sur votre code PySpark¶
Le paquet snowpark-checkpoints-collectors propose une fonction permettant d’extraire des informations des DataFrames PySpark. Nous pouvons ensuite utiliser ces données pour les comparer aux données converties des DataFrames Snowpark afin de garantir l’équivalence des comportements.
Utilisez la fonction suivante pour insérer un nouveau point de collecte des points de contrôle :
Signature de la fonction :
def collect_dataframe_checkpoint(df: SparkDataFrame,
checkpoint_name: str,
sample: Optional[float],
mode: Optional[CheckpointMode],
output_path: Optional[str]) -> None:
Paramètres de fonction :
df : le DataFrame PySpark.
checkpoint_name : le nom du point de contrôle. Commence par une lettre (A-Z, a-z) ou un trait de soulignement (_) et ne contient que des lettres, des traits de soulignement et des chiffres décimaux (0-9).
échantillon : (facultatif) la taille de l’échantillon. La valeur par défaut est 1.0 (DataFramePySpark) dans une plage de 0 à 1.0.
mode : (facultatif) le mode d’exécution. Les options sont
SCHEMAetDATAFRAME. La valeur par défaut estSCHEMA.output_path : (facultatif) le chemin de sortie pour enregistrer le point de contrôle. La valeur par défaut est le répertoire de travail actuel.
Le processus de collecte génère un fichier de sortie, appelé checkpoint_collection_result.json, contenant les informations relatives au résultat pour chaque point de collecte. Il s’agit d’un fichier JSON qui contient les informations suivantes :
Horodatage du début du point de collecte.
Le chemin relatif du fichier où se trouve le point de collecte.
La ligne de code du fichier où se trouve le point de collecte.
Nom du point de contrôle du point de collecte.
Le résultat du point de collecte (échec ou réussite).
Mode de collecte des données par inférence de schéma (schéma)¶
Il s’agit du mode par défaut, qui s’appuie sur l’inférence du schéma Pandera pour obtenir les métadonnées et les contrôles qui seront évalués pour le DataFrame spécifié. Ce mode permet également de collecter des données personnalisées dans les colonnes du DataFrame en fonction du type PySpark.
Les données et les contrôles de la colonne sont collectés en fonction du type PySpark de la colonne (voir les tables ci-dessous). Pour toute colonne, quel que soit son type, les données personnalisées collectées incluront le nom de la colonne, le type de la colonne, Null possible, le nombre de lignes, le nombre de lignes non nulles et le nombre de lignes nulles.
Type de colonne |
Données personnalisées collectées |
|---|---|
Numérique ( |
La valeur minimale. La valeur maximale. La valeur moyenne. La précision décimale (dans le cas d’un type entier, la valeur est zéro). L’écart-type. |
Date |
La valeur minimale. La valeur maximale. Le format de la date : %Y-%m-%d |
DayTimeIntervalType et YearMonthIntervalType |
La valeur minimale. La valeur maximale. |
Horodatage |
La valeur minimale. La valeur maximale. Le format de la date : %Y-%m-%dH:%M:%S |
Horodatage ntz |
La valeur minimale. La valeur maximale. Le format de la date : %Y-%m-%dT%H:%M:%S%z |
Chaîne |
La valeur de la longueur minimale. La valeur de la longueur maximale. |
Char |
PySpark traite tout littéral comme un type de chaîne, par conséquent char n’est pas un type valide. |
Varchar |
PySpark traite tout littéral comme un type de chaîne, par conséquent Varchar n’est pas un type valide. |
Décimal |
La valeur minimale. La valeur maximale. La valeur moyenne. La précision décimale. |
Tableau |
Le type de la valeur. Si autorisé, null en tant qu’élément. La proportion de valeurs nulles. La taille maximale du tableau. La taille minimale du tableau. La taille moyenne des tableaux. Si tous les tableaux ont la même taille. |
Binaire |
La taille maximale. La taille minimale. La taille moyenne. Si tous les éléments ont la même taille. |
Map |
Le type de la clé. Le type de la valeur. Si autorisé, null comme valeur. La proportion de valeurs nulles. La taille maximale du mappage. La taille minimale du mappage. La taille moyenne des mappages. Si toutes les mappages ont la même taille. |
Nul |
NullType représente Aucun, car les données du type ne peuvent pas être déterminées ; il n’est donc pas possible d’obtenir des informations à partir de ce type. |
Struct |
Les métadonnées de la struct, c’est pour chaque structField : |
Il définit également un ensemble de contrôles de validation prédéfinis pour chaque type de données, détaillés dans la table suivante :
Type |
Contrôles Pandera |
Contrôles supplémentaires |
|---|---|---|
Booléen |
Chaque valeur est Vrai ou Faux. |
Le nombre de valeurs vraies et fausses. |
Numérique ( |
Chaque valeur est comprise entre la valeur minimale et la valeur maximale. |
La précision décimale. La valeur moyenne. L’écart-type. |
Date |
N/A |
Valeurs minimales et maximales. |
Horodatage |
Chaque valeur est comprise entre la valeur minimale et la valeur maximale. |
Le format de la valeur. |
Horodatage ntz |
Chaque valeur est comprise entre la valeur minimale et la valeur maximale. |
Le format de la valeur. |
Chaîne |
La longueur de chaque valeur est comprise entre la longueur minimale et la longueur maximale. |
Aucun(e) |
Char |
PySpark traite tout littéral comme un type de chaîne, par conséquent |
|
Varchar |
PySpark traite tout littéral comme un type de chaîne, par conséquent |
|
Décimal |
N/A |
N/A |
Tableau |
N/A |
Aucun(e) |
Binaire |
N/A |
Aucun(e) |
Map |
N/A |
Aucun(e) |
Nul |
N/A |
N/A |
Struct |
N/A |
Aucun(e) |
Ce mode permet à l’utilisateur de définir un échantillon de DataFrame à collecter, mais il est facultatif. Par défaut, la collection fonctionne avec l’ensemble du DataFrame. La taille de l’échantillon doit être statistiquement représentative de la population.
Pandera ne peut que déduire le schéma d’un DataFrame Pandas, ce qui implique que le DataFrame PySpark doit être converti en un DataFrame Pandas, ce qui peut affecter les résolutions de type des colonnes. En particulier, Pandera déduit les types PySpark suivants en tant que types d’objets : string, array, map, null, struct et binary.
La sortie de ce mode est un fichier JSON pour chaque DataFrame collecté, le nom du fichier étant le même que celui du point de contrôle. Ce fichier contient des informations relatives au schéma et comporte deux sections :
La section du schéma Pandera contient les données déduites par Pandera telles que le nom, le type (Pandas), si la colonne autorise les valeurs nulles ou non, et d’autres informations pour chaque colonne, ainsi que les vérifications des colonnes basées sur le type PySpark. Il s’agit d’un objet
DataFrameSchemade Pandera.La section des données personnalisées est un tableau des données personnalisées collectées par chaque colonne en fonction du type PySpark.
Note
Le paquet de collecte peut avoir des problèmes de mémoire lorsqu’il traite des DataFramesPySpark volumineux. Pour remédier à ce problème, vous pouvez définir le paramètre de l’échantillon dans la fonction de collecte à une valeur comprise entre 0.0 et 1.0, afin de travailler avec un sous-ensemble de données au lieu de l’ensemble du DataFrame PySpark.
Mode de données DataFrame collectées (DataFrame)¶
Ce mode permet de collecter les données du DataFrame PySpark. Dans ce cas, le mécanisme enregistre toutes les données du DataFrame donné au format Parquet. En utilisant la connexion par défaut de l’utilisateur Snowflake, il tente de télécharger les fichiers Parquet dans la zone de préparation temporelle de Snowflake et de créer une table sur la base des informations contenues dans la phase. Le nom du fichier et de la table est le même que celui du point de contrôle.
La sortie de ce mode est un fichier Parquet résultat de l’enregistrement du DataFrame et une table avec les données du DataFrame dans la connexion de configuration par défaut de Snowflake.
Valider le code converti de Snowpark¶
Le paquet Snowpark Checkpoints offre un ensemble de paramètres de validation qui peuvent être appliqués au code Snowpark afin de garantir l’équivalence comportementale avec le code PySpark.
Les fonctions offertes par le cadre¶
check_with_spark : un décorateur qui convertira tout argument du DataFrame Snowpark en une fonction ou un échantillon, puis en DataFrames PySpark. Le contrôle exécutera ensuite une fonction spark fournie qui reflète la fonctionnalité de la nouvelle fonction Snowpark et comparera les sorties entre les deux implémentations. En supposant que la fonction spark et les fonctions Snowpark sont sémantiquement identiques, cela permet de vérifier ces fonctions sur des données réelles et échantillonnées.
- Paramètres :
job_context(SnowparkJobContext) : le contexte de la tâche contenant la configuration et les détails de la validation.spark_function(fn) : la fonction PySpark équivalente pour comparer avec l’implémentation Snowpark.checkpoint_name(str) : nom du point de contrôle. La valeur par défaut est Aucun.sample_number(Optional[int], optional) : le nombre de lignes pour la validation. La valeur par défaut est 100.sampling_strategy(Optional[SamplingStrategy], optional) : la stratégie utilisée pour l’échantillonnage des données. La valeur par défaut estSamplingStrategy.RANDOM_SAMPLE.output_path(Optional[str], optional) : le chemin pour stocker les résultats de la validation. La valeur par défaut est Aucun.
Voici un exemple :
def original_spark_code_I_dont_understand(df): from pyspark.sql.functions import col, when ret = df.withColumn( "life_stage", when(col("byte") < 4, "child") .when(col("byte").between(4, 10), "teenager") .otherwise("adult"), ) return ret @check_with_spark( job_context=job_context, spark_function=original_spark_code_I_dont_understand ) def new_snowpark_code_I_do_understand(df): from snowflake.snowpark.functions import col, lit, when ref = df.with_column( "life_stage", when(col("byte") < 4, lit("child")) .when(col("byte").between(4, 10), lit("teenager")) .otherwise(lit("adult")), ) return ref df1 = new_snowpark_code_I_do_understand(df)
validate_dataframe_checkpoint : cette fonction valide un Dataframe Snowpark par rapport à un fichier de schéma de point de contrôle spécifique ou un Dataframe importé selon le mode de l’argument. Elle garantit que les informations collectées pour ce DataFrame et le DataFrame transmis à la fonction sont équivalents.
- Paramètres :
df(SnowparkDataFrame) : le DataFrame à valider.checkpoint_name(str) : le nom du point de contrôle auquel la validation doit être effectuée.job_context(SnowparkJobContext, optional) (str) : le contexte de la tâche pour la validation. Obligatoire pour le mode PARQUET.mode(CheckpointMode) : le mode de validation (par exemple, SCHEMA, PARQUET). La valeur par défaut est SCHEMA.custom_checks(Optional[dict[Any, Any]], optional) : Vérifications personnalisées à appliquer lors de la validation.skip_checks(Optional[dict[Any, Any]], optional) : contrôles à ignorer lors de la validation.sample_frac(Optional[float], optional) : fraction du DataFrame à échantillonner pour la validation. La valeur par défaut est 0.1.sample_number(Optional[int], optional) : nombre de lignes à échantillonner pour la validation.sampling_strategy(Optional[SamplingStrategy], Optional) : stratégie à utiliser pour l’échantillon.output_path(Optional[str], optional) : le chemin de sortie des résultats de la validation.
Voici un exemple :
# Check a schema/stats here! validate_dataframe_checkpoint( df1, "demo_add_a_column_dataframe", job_context=job_context, mode=CheckpointMode.DATAFRAME, # CheckpointMode.Schema) )
En fonction du mode choisi, la validation utilisera soit le fichier de schéma collecté, soit un Dataframe chargé par Parquet dans Snowflake pour vérifier l’équivalence par rapport à la version PySpark.
check-ouput_schema : ce décorateur valide le schéma de la sortie d’une fonction Snowpark et s’assure que le DataFrame de sortie est conforme à un schéma Pandera spécifié. Il est particulièrement utile pour assurer l’intégration et la cohérence des données dans les pipelines Snowpark. Ce décorateur prend plusieurs paramètres, dont le schéma Pandera à valider, le nom du point de contrôle, les paramètres d’échantillonnage et un contexte de tâche optionnelle. Il enveloppe la fonction Snowpark et effectue une validation de schéma sur le DataFrame de sortie avant de renvoyer le résultat.
Voici un exemple :
from pandas import DataFrame as PandasDataFrame from pandera import DataFrameSchema, Column, Check from snowflake.snowpark import Session from snowflake.snowpark import DataFrame as SnowparkDataFrame from snowflake.snowpark_checkpoints.checkpoint import check_output_schema from numpy import int8 # Define the Pandera schema out_schema = DataFrameSchema( { "COLUMN1": Column(int8, Check.between(0, 10, include_max=True, include_min=True)), "COLUMN2": Column(float, Check.less_than_or_equal_to(-1.2)), "COLUMN3": Column(float, Check.less_than(10)), } ) # Define the Snowpark function and apply the decorator @check_output_schema(out_schema, "output_schema_checkpoint") def preprocessor(dataframe: SnowparkDataFrame): return dataframe.with_column( "COLUMN3", dataframe["COLUMN1"] + dataframe["COLUMN2"] ) # Create a Snowpark session and DataFrame session = Session.builder.getOrCreate() df = PandasDataFrame( { "COLUMN1": [1, 4, 0, 10, 9], "COLUMN2": [-1.3, -1.4, -2.9, -10.1, -20.4], } ) sp_dataframe = session.create_dataframe(df) # Apply the preprocessor function preprocessed_dataframe = preprocessor(sp_dataframe)
check_input_schema : ce décorateur valide le schéma des arguments d’entrée d’une fonction Snowpark. Ce décorateur garantit que le DataFrame d’entrée est conforme à un schéma Pandera spécifié avant l’exécution de la fonction. Il est particulièrement utile pour assurer l’intégration et la cohérence des données dans les pipelines Snowpark. Ce décorateur prend plusieurs paramètres, dont le schéma Pandera à valider, le nom du point de contrôle, les paramètres d’échantillonnage et un contexte de tâche optionnelle. Il enveloppe la fonction Snowpark et effectue une validation de schéma sur le DataFrame d’entrée avant d’exécuter la fonction.
Voici un exemple :
from pandas import DataFrame as PandasDataFrame from pandera import DataFrameSchema, Column, Check from snowflake.snowpark import Session from snowflake.snowpark import DataFrame as SnowparkDataFrame from snowflake.snowpark_checkpoints.checkpoint import check_input_schema from numpy import int8 # Define the Pandera schema input_schema = DataFrameSchema( { "COLUMN1": Column(int8, Check.between(0, 10, include_max=True, include_min=True)), "COLUMN2": Column(float, Check.less_than_or_equal_to(-1.2)), } ) # Define the Snowpark function and apply the decorator @check_input_schema(input_schema, "input_schema_checkpoint") def process_dataframe(dataframe: SnowparkDataFrame): return dataframe.with_column( "COLUMN3", dataframe["COLUMN1"] + dataframe["COLUMN2"] ) # Create a Snowpark session and DataFrame session = Session.builder.getOrCreate() df = PandasDataFrame( { "COLUMN1": [1, 4, 0, 10, 9], "COLUMN2": [-1.3, -1.4, -2.9, -10.1, -20.4], } ) sp_dataframe = session.create_dataframe(df) # Apply the process_dataframe function processed_dataframe = process_dataframe(sp_dataframe)
Contrôles statistiques¶
Les validations statistiques sont appliquées par défaut au type de colonne spécifique lorsque la validation est exécutée en mode Schema ; ces contrôles peuvent être ignorés avec skip_checks.
Type de colonne |
Contrôle par défaut |
|---|---|
Numérique : |
entre : si la valeur est comprise entre le min ou le max, y compris le min et le max. decimal_precision : si la valeur est décimale, ceci vérifiera la précision décimale. moyenne : validez si la moyenne des colonnes est comprise dans une plage spécifique. |
Booléen |
isin : validez si la valeur est Vrai ou Faux. True_proportion : validez si la proportion des valeurs Vrai se situe dans une plage spécifique. False_proportion : validation si la proportion des valeurs Faux est comprise dans une plage spécifique. |
Date : |
entre : si la valeur est comprise entre le min ou le max, y compris le min et le max. |
Null possible : tous les types pris en charge |
Null_proportion : validez la proportion nulle en conséquence. |
Ignorer les contrôles¶
Il existe un contrôle granulaire des contrôles, qui vous permet d’ignorer la validation d’une colonne ou des contrôles spécifiques pour une colonne. Avec le paramètre skip_checks, vous pouvez spécifier la colonne particulière et le type de validation que vous souhaitez ignorer. Le nom du contrôle utilisé à ignorer est celui qui est associé au contrôle.
str_containsstr_endswithstr_lengthstr_matchesstr_startswithin_rangeequal_togreater_than_or_equal_togreater_thanless_than_or_equal_toless_thannot_equal_tonotinisin
df = pd.DataFrame(
{
"COLUMN1": [1, 4, 0, 10, 9],
"COLUMN2": [-1.3, -1.4, -2.9, -10.1, -20.4],
}
)
schema = DataFrameSchema(
{
"COLUMN1": Column(int8, Check.between(0, 10, element_wise=True)),
"COLUMN2": Column(
float,
[
Check.greater_than(-20.5),
Check.less_than(-1.0),
Check(lambda x: x < -1.2),
],
),
}
)
session = Session.builder.getOrCreate()
sp_df = session.create_dataframe(df)
check_dataframe_schema(
sp_df,
schema,
skip_checks={"COLUMN1": [SKIP_ALL], "COLUMN2": ["greater_than", "less_than"]},
)
Contrôles personnalisés¶
Vous pouvez ajouter des contrôles supplémentaires au schéma généré à partir du fichier JSON à l’aide de la propriété custom_checks. Cette opération ajoutera le contrôle au schéma pandera :
df = pd.DataFrame(
{
"COLUMN1": [1, 4, 0, 10, 9],
"COLUMN2": [-1.3, -1.4, -2.9, -10.1, -20.4],
}
)
session = Session.builder.getOrCreate()
sp_df = session.create_dataframe(df)
# Those check will be added to the schema generate from the JSON file
result = validate_dataframe_checkpoint(
sp_df,
"checkpoint-name",
custom_checks={
"COLUMN1": [
Check(lambda x: x.shape[0] == 5),
Check(lambda x: x.shape[1] == 2),
],
"COLUMN2": [Check(lambda x: x.shape[0] == 5)],
},
)
Stratégies d’échantillonnage¶
Le processus d’échantillonnage du code fourni est conçu pour valider efficacement de larges DataFrames en prenant un échantillon représentatif des données. Cette approche permet d’effectuer la validation des schémas sans avoir à traiter l’ensemble des données, ce qui peut s’avérer coûteux en temps et en argent.
- Paramètres :
sample_frac: ce paramètre indique la fraction du DataFrame à échantillonner. Par exemple, sisample_fracest défini sur 0.1, 10 % des lignes du DataFrame seront échantillonnées. Ceci est utile lorsque vous souhaitez valider un sous-ensemble de données afin d’économiser les ressources calcul.sample_number: ce paramètre indique le nombre exact de lignes à échantillonner dans le DataFrame. Par exemple, sisample_numberest défini sur 100, 100 lignes seront échantillonnées dans le DataFrame. Cette fonction est utile lorsque vous souhaitez valider un nombre fixe de lignes, quelle que soit la taille du DataFrame.
Résultat de validation¶
Après l’exécution de tout type de validation, le résultat, qu’il soit positif ou négatif, est enregistré sur checkpoint_validation_results.json. Ce fichier est principalement utilisé pour les fonctionnalités de l’extension VSCode. Il contient des informations sur le statut de la validation, l’horodatage, le nom du point de contrôle, le numéro de la ligne où se produit l’exécution de la fonction et le fichier.
Il consignera également le résultat dans le compte Snowflake par défaut dans une table appelée SNOWPARK_CHECKPOINTS_REPORT, qui contiendra des informations sur le résultat de la validation.
DATE: horodatage d’exécution de la validation.JOB: nom du SnowparkJobContext.STATUS: statut de la validation.CHECKPOINT: nom du point de contrôle validé.MESSAGE: message d’erreurDATA: données de l’exécution de la validation.EXECUTION_MODE: le mode de validation est exécuté.
Variable d’environnement du point de contrôle¶
Le comportement par défaut du cadre pour trouver le fichier checkpoints.json est de rechercher une variable d’environnement appelée SNOWFLAKE_CHECKPOINT_CONTRACT_FILE_PATH_ENV_VAR. Cette variable contiendra le chemin relatif de checkpoint.json. Il est attribué par l’extension VSCode lorsque vous exécutez le point de contrôle avec les lentilles de code dans le code. Si la variable d’environnement n’est pas attribuée, le cadre essaiera de rechercher le fichier dans le répertoire de travail actuel.
Test unitaire Hypothesis¶
Hypothesis est une puissante bibliothèque de tests pour Python conçue pour améliorer les tests unitaires traditionnels en générant automatiquement un large éventail de données d’entrée. Elle utilise des tests basés sur les propriétés, où au lieu de spécifier des cas de test individuels, vous pouvez décrire le comportement attendu de votre code avec des propriétés ou des conditions. Hypothesis génère des exemples pour tester ces propriétés en profondeur. Cette approche permet de découvrir les cas limites et les comportements inattendus, ce qui la rend particulièrement efficace pour les fonctions complexes. Pour plus d’informations, voir Hypothesis.
Le paquet snowpark-checkpoints-hypothesis étend la bibliothèque Hypothesis pour générer des DataFrames Snowpark synthétiques à des fins de test. En tirant parti de la possibilité qu’offre Hypothesis de générer des données de test diverses et aléatoires, vous pouvez créer des DataFrames Snowpark avec des schémas et des valeurs variés pour simuler des scénarios réels et découvrir des cas limites, en garantissant la robustesse du code et en vérifiant l’exactitude des transformations complexes.
La stratégie d’Hypothesis pour Snowpark s’appuie sur Pandera pour générer des données synthétiques. La fonction dataframe_strategy utilise le schéma spécifié pour générer un DataFrame Pandas qui s’y conforme et le convertit ensuite en un DataFrame Snowpark.
Signature de la fonction :
def dataframe_strategy(
schema: Union[str, DataFrameSchema],
session: Session,
size: Optional[int] = None
) -> SearchStrategy[DataFrame]
Paramètres de fonction :
schema: le schéma qui définit les colonnes, les types de données et les contrôles auxquels le dataframe Snowpark généré doit correspondre. Le schéma peut être le suivant :Un chemin vers un fichier de schéma JSON généré par la fonction
collect_dataframe_checkpointdu paquetsnowpark-checkpoints-collectors.Une instance de pandera.api.pandas.container.DataFrameSchema.
session: une instance de snowflake.snowpark.Session qui sera utilisée pour créer les DataFrames Snowpark.size: le nombre de lignes à générer pour chaque DataFrame Snowpark. Si ce paramètre n’est pas fourni, la stratégie générera des DataFrames de tailles différentes.
Sortie de fonction :
Renvoie une SearchStrategy Hypothesis qui génère des DataFrames Snowpark.
Types de données pris en charge et non pris en charge¶
La fonction dataframe_strategy permet de générer les DataFrames Snowpark avec différents types de données. Selon le type de l’argument du schéma transmis à la fonction, les types de données pris en charge par la stratégie varieront. Notez que si la stratégie trouve un type de données non pris en charge, elle lèvera une exception.
Le tableau suivant indique les types de données PySpark pris en charge et non pris en charge par la fonction dataframe_strategy lorsqu’un fichier JSON est transmis en tant qu’argument schema.
Type de données PySpark |
Pris en charge |
|---|---|
Oui |
|
Oui |
|
Non |
|
Oui |
|
Non |
|
Non |
|
Non |
|
Non |
|
Oui |
|
Oui |
|
Non |
|
Oui |
|
Oui |
|
Non |
|
Non |
La table suivante présente les types de données Pandera pris en charge par la fonction dataframe_strategy lorsqu’elle transmet un objet DataFrameSchema en tant qu’argument schema et les types de données Snowpark auxquels ils sont mappés.
Type de données Pandera |
Type de données Snowpark |
|---|---|
int8 |
|
int16 |
|
int32 |
|
int64 |
|
float32 |
|
float64 |
|
chaîne |
|
bool |
|
datetime64[ns, tz] |
|
datetime64[ns] |
|
date |
Exemples¶
Le processus typique d’utilisation de la bibliothèque Snowpark pour générer les DataFrames est le suivant :
Créez une fonction de test Python standard avec les différentes assertions ou conditions que votre code doit satisfaire pour toutes les entrées.
Ajoutez le décorateur Hypothesis
@givenà votre fonction de test et passez la fonctiondataframe_strategyen argument. Pour plus d’informations sur le décorateur@given, voir hypothesis.given.Exécutez la fonction de test. Lors de l’exécution du test, Hypothesis fournira automatiquement les entrées générées comme arguments au test.
Exemple 1 : générer les DataFrames de Snowpark à partir d’un fichier JSON
Vous trouverez ci-dessous un exemple de génération de DataFrames Snowpark à partir d’un fichier de schéma JSON généré par la fonction collect_dataframe_checkpoint du paquet snowpark-checkpoints-collectors.
from hypothesis import given
from snowflake.hypothesis_snowpark import dataframe_strategy
from snowflake.snowpark import DataFrame, Session
@given(
df=dataframe_strategy(
schema="path/to/file.json",
session=Session.builder.getOrCreate(),
size=10,
)
)
def test_my_function_from_json_file(df: DataFrame):
# Test a particular function using the generated Snowpark DataFrame
...
Exemple 2 : générer un DataFrame Snowpark à partir d’un objet DataFrameSchema Pandera
Vous trouverez ci-dessous un exemple de la manière de générer les DataFrames Snowpark à partir d’une instance de DataFrameSchema Pandera. Pour plus d’informations, voir DataFrameSchema Pandera.
import pandera as pa
from hypothesis import given
from snowflake.hypothesis_snowpark import dataframe_strategy
from snowflake.snowpark import DataFrame, Session
@given(
df=dataframe_strategy(
schema=pa.DataFrameSchema(
{
"boolean_column": pa.Column(bool),
"integer_column": pa.Column("int64", pa.Check.in_range(0, 9)),
"float_column": pa.Column(pa.Float32, pa.Check.in_range(10.5, 20.5)),
}
),
session=Session.builder.getOrCreate(),
size=10,
)
)
def test_my_function_from_dataframeschema_object(df: DataFrame):
# Test a particular function using the generated Snowpark DataFrame
...
Exemple 3 : personnaliser le comportement d’Hypothesis
Vous pouvez également personnaliser le comportement de votre test à l’aide du décorateur Hypothesis @settings. Ce décorateur vous permet de personnaliser divers paramètres de configuration afin d’adapter le comportement du test à vos besoins. En utilisant le décorateur @settings, vous pouvez contrôler des aspects tels que le nombre maximum de cas de test, la date limite pour chaque exécution de test, les niveaux de verbosité et bien d’autres. Pour plus d’informations, voir Paramètres d’Hypothesis.
from datetime import timedelta
from hypothesis import given, settings
from snowflake.snowpark import DataFrame, Session
from snowflake.hypothesis_snowpark import dataframe_strategy
@given(
df=dataframe_strategy(
schema="path/to/file.json",
session=Session.builder.getOrCreate(),
)
)
@settings(
deadline=timedelta(milliseconds=800),
max_examples=25,
)
def test_my_function(df: DataFrame):
# Test a particular function using the generated Snowpark DataFrame
...
Configuration d’un IDE pour les points de contrôle Snowpark¶
L”extension Snowflake pour Visual Studio Code offre un support pour la bibliothèque Snowpark Checkpoints afin d’améliorer l’expérience d’utilisation du cadre. Elle vous permet de contrôler finement les instructions collect et validate insérées dans votre code, ainsi que de vérifier le statut des assertions d’équivalence comportementale de votre code converti.
Mise en place de points de contrôle Snowparks¶
Pour activer les points de contrôle Snowpark, allez dans les paramètres d’extension de Snowflake et cochez Snowpark Checkpoints: Enabled.

Vue¶
En définissant la propriété des points de contrôle Snowpark sur Enabled, comme expliqué précédemment, vous ouvrirez un nouvel onglet dans l’extension appelé SNOWPARK CHECKPOINTS. Il affiche tous les points de contrôle dans l’espace de travail et permet d’effectuer plusieurs actions, telles que l’activation/désactivation de tous les points de contrôle ou d’un seul d’entre eux, l’effacement de tous les fichiers et, en double-cliquant sur chaque point de contrôle, la navigation vers le fichier et la ligne de code où il est défini.
Basculer tous les points de contrôle¶
Située en haut à droite de l’onglet Snowpark Checkpoints, cette option permet d’activer la propriété dans tous les points de contrôle.
Points de contrôle activés :
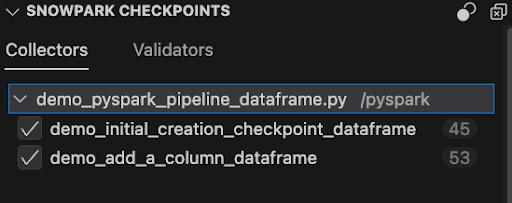
La désactivation d’un point de contrôle a pour effet de l’ignorer lors de l’environnement d’exécution.

Nettoyage de tous les points de contrôle¶
Situé dans le coin supérieur droit de l’onglet Snowpark Checkpoints. Cela supprime les points de contrôle de tous les fichiers Python, y compris les Notebooks Jupyter, dans votre espace de travail, mais cela ne les supprime pas du contrat et du panneau. Cela signifie qu’ils peuvent être restaurés à l’aide de la commande Snowflake: Restore All Checkpoints.
Insertion de points de contrôle dans un fichier¶
En cliquant avec le bouton droit de la souris à l’intérieur d’un fichier, vous ferez apparaître un menu contextuel contenant l’option Snowpark Checkpoints, qui permet d’ajouter des points de contrôle Collection et Validation.
Option des points de contrôle Snowpark dans le menu contextuel :

Ajout d’un collecteur/validateur :

Exécution d’un seul point de contrôle¶
Un seul point de contrôle peut être exécuté en cliquant sur l’option de lentille de code affichée au-dessus de chaque point de contrôle. Son exécution fait apparaître une console de sortie montrant la progression et, une fois qu’elle est terminée, la vue des résultats. Même si le point de contrôle est désactivé dans le fichier de contrat, il sera activé juste pour son exécution.

Si un point d’entrée n’est pas déclaré dans le fichier des contrats, le message d’erreur : Point d’entrée non trouvé pour le point de contrôle. s’affiche.

Exécution de tous les points de contrôle Snowpark activés dans un fichier¶
Dans le coin supérieur droit de chaque fichier, le bouton Run all checkpoints from the current file est présent.

En cliquant dessus, vous ferez apparaître un canal de sortie affichant la progression de l’exécution.

Vue de la ligne du temps¶
Affiche une chronologie des résultats de l’exécution des points de contrôle.

Commandes¶
Les commandes suivantes sont disponibles pour les points de contrôle Snowpark. Pour les utiliser, entrez Snowflake: [command name] dans la palette de commandes.
Commande |
Description |
|---|---|
Snowflake : basculer les points de contrôle |
Bascule la propriété activée de tous les points de contrôle. |
Snowflake : initialisation du projet de points de contrôle Snowpark |
Déclenche l’initialisation du projet, en créant un fichier de contrat s’il n’existe pas. Dans le cas où il existe, une fenêtre contextuelle s’affiche, vous demandant si vous souhaitez charger le point de contrôle dans le fichier du contrat. |
Snowflake : effacer tous les points de contrôle |
Supprime tous les points de contrôle de tous les fichiers de l’espace de travail. |
Snowflake : restaurer tous les points de contrôle |
Restaure les points de contrôle précédemment supprimés des fichiers qui sont toujours présents dans le fichier de contrat. |
Snowflake : ajouter un point de contrôle de validation/collecte |
Ajoute un validateur ou un collecteur avec ses paramètres obligatoires à la position du curseur. |
Snowflake : focus sur la vue des points de contrôle Snowpark |
L’accent est mis sur le panneau SNOWPARK CHECKPOINTS. |
Snowflake : calendrier des points de contrôle ouverts |
Affiche une chronologie des exécutions des points de contrôle. |
Snowflake : exécuter tous les points de contrôle à partir du fichier actuel |
Exécute tous les points de contrôle activés dans le fichier actuel. |
Snowflake : exécuter tous les points de contrôle dans l’espace de travail |
Exécute tous les points de contrôle activés à partir de l’espace de travail. |
Snowflake : afficher tous les résultats des points de contrôle Snowpark |
Affiche un onglet avec tous les résultats des points de contrôle. |
Avertissements¶
Dupliquer : dans un projet de collecte, si deux points de contrôle portent le même nom, un avertissement s’affiche : « Un autre point de contrôle portant un nom identique a été détecté et sera écrasé. » Les projets de validation peuvent avoir plusieurs points de contrôle partageant le même nom, aucun avertissement ne sera affiché.
Mauvais type : l’ajout d’un point de contrôle d’un type différent de celui du projet le soulignera avec le message d’erreur suivant : « Veuillez vous assurer que vous utilisez la bonne instruction pour les points de contrôle Snowpark. Cette instruction de point de contrôle particulière est différente des autres utilisées dans ce projet, les instructions qui ne correspondent pas au type de projet seront ignorées lors de leur exécution. »
Nom de point de contrôle non valide : il existe des façons non valides d’ajouter un paramètre de nom de point de contrôle. Dans ce cas, un message d’avertissement s’affiche : « Nom de point de contrôle non valide. Les noms des points de contrôle doivent commencer par une lettre et ne peuvent contenir que des lettres, des chiffres, des traits d’union et des traits de soulignement ».